This page contains the collection of messages from Twitter
in the Italian language that is continuously going on since 2012 at the
University of Turin. A number of smaller datasets have been extracted
from the main collection and enriched with different kinds of annotations
for linguistic purposes. Moreover, a few extra datasets have been collected
independently and are now in the process of being merged with the main
collection.
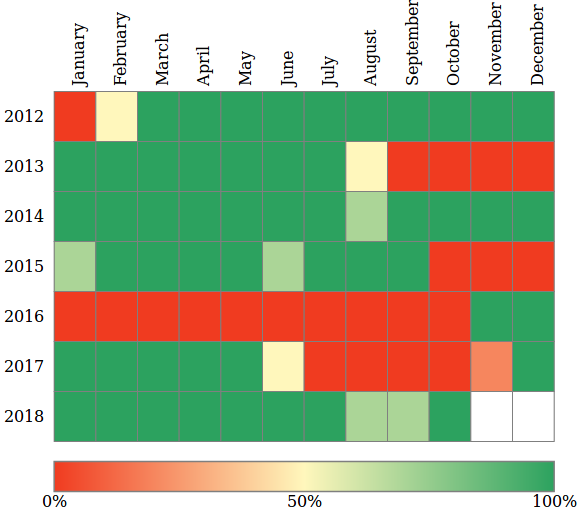
This figure shows the coverage of TWITA up to September 2018,
in terms of percentage of days in each months for which data are available in the collection.
We make the resource available to the community to the best of our possibility, in accordance with the Twitter Terms of Service.
TWITA Datasets:
40wita
Collection of tweets about the COVID-19 emergency in Italy.
ConRef-STANCE-ita
collection of tweets on the topic of the Referendum held in Italy on December 4, 2016, about a reform of the Italian Constitution.
Felicittà
Corpus for the evaluation of a project on the development of a platform that aimed to estimate and interactively display the degree of happiness in Italian cities.
HaSpeeDe
Dataset for the Hate Speech Detection task at EVALITA 2018.
Italian Hate Speech Corpus
Corpus of hate speech on social media towards migrants and ethnic minorities.
IronITA
Dataset for the irony detection task task at EVALITA 2018.
PoSTWITA
Dataset for the SENTIment POLarity Classification task at EVALITA 2014 and 2016.
Senti-TUT
A dataset of Italian tweets with a focus on politics and ironic content.
SENTIPOLC
Dataset for the SENTIment POLarity Classification task at EVALITA 2014 and 2016.
TW-BuonaScuola
Corpus of Italian tweets on the topic of the national educational and training systems.
TW-SWELLFER
Corpus of Italian tweets on subjective well-being, in particular regarding the topics of fertility and parenthood.
TWITTIRÒ
Dataset of Italian tweets a fine-grained annotation of irony is superimposed.